
什么是Java序列化与反序列化?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文主要介绍如上三点内容。
java实现多线程的三种方式
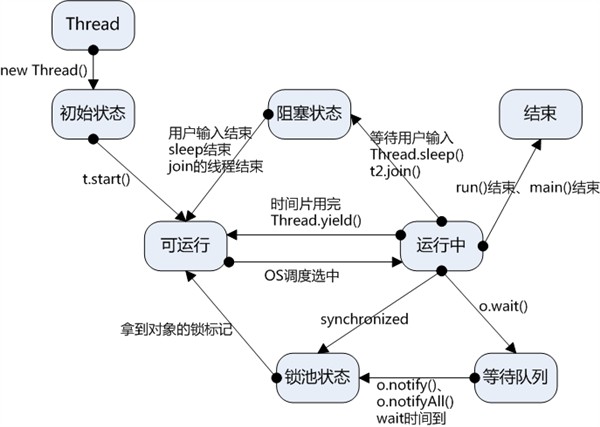
总结实现多线程的三种方式。(上图为多线程的生命周期图,本文不涉及,总结的很好,我就贴过来了…)
单例模式(一)

单例模式是最简单最常见的设计模式之一。单例模式的学习教程一般都会提到饿汉式、懒汉式,其中体现了单例模式最要关心的两个问题:对象创建的次数以及何时被创建。 本文会着重总结如上两类实现方式。
scrapy:爬取北邮人论坛所有帖的基本信息及正文

参考代码来自于这里,算是二次加工吧。但我其实基本上重写了所有代码,item的定义,spider的逻辑,pipline的数据处理存储等,不过论坛信息爬取的思路分析,模拟登陆及cookie传递都是受原始代码的启发而来,感谢原作者buptbill200。在腾讯的云服务器上跑过几次,基本功能能跑通,但还有不完善之处,比如帖子的主体信息处理与存储部分。
hexo小技巧-首页显示文章摘要及图片
hexo问题-hexo s本地测试失败,但hexo d部署正常
问题描述:hexo s ,hexo d运行正常,能通过username.github.io查看内容,但在浏览器中无法通过http: //localhost:4000/访问本地服务,显示“404”。
python装饰器与语法糖@

当想为写好的函数添加新功能而又不想或不方便更改原函数时,就可以使用装饰器来解决,如添加计时器,日志记录,权限认证等,有人将此概括为有切面需求的场景。简单来说,就是为已有的对象添加附加功能,就好像在进行“装饰”。
git的基本使用

scrapy安装步骤

scrapy是Python中一款相当知名的爬虫框架,spiders,downloader,pipline各部分组件分工明确,上手简单,使用了一段时间,虽然还有很多高级组件还接触过,但已经臣服于它的简洁优雅。本文主要介绍安装步骤(基于64位的windows10系统)。
在新电脑上配置环境,更新hexo博客

重装电脑系统,或者换了个新的电脑,如果想要继续更新博客,就得重新配置相关环境,其实主要是配置git。
递归练习

这几道题目难度都不大,甚至有些不用递归会有更简洁的方式实现。但强制自己用递归实现出来,对于学习这种解决问题的方法还是有帮助的。
对于判断出能用递归解决的问题,可以先把“归”确定下来,然后再想如何“递”,并把“递”的各种情况考虑清楚、完善,整道题目应该就解决得差不多了。
Tkinter实践
![]()
Tkinter模块是Python的标准Tk GUI工具包的接口,可以在大多数的Unix平台下使用,同样可以应用在Windows和Macintosh系统里,是一款简单易用的跨平台python库。