
参考代码来自于这里,算是二次加工吧。但我其实基本上重写了所有代码,item的定义,spider的逻辑,pipline的数据处理存储等,不过论坛信息爬取的思路分析,模拟登陆及cookie传递都是受原始代码的启发而来,感谢原作者buptbill200。在腾讯的云服务器上跑过几次,基本功能能跑通,但还有不完善之处,比如帖子的主体信息处理与存储部分。
完整代码下载
- 通过git:git clone https://github.com/ryderchan/byrbbs.git
- 访问地址:https://github.com/ryderchan/byrbbs
功能
爬取北邮人论坛十个主要板块的板块信息,包括子版块信息,板块的总帖数。针对每一个板块,爬取板块内的所有帖子,包括作者,上传时间,回帖数等等。并获取帖子的主体内容。以上信息均存储与Mysql中。
环境与工具
- windows 10 64位 专业版
- java 版本 1.8.0_111
- Mysql 版本 5.7
- python 版本 2.7.12(anaconda4.2 64位)
- scrapy
- re
- MySQLdb
- functools
scrapy基本原理
scrapy有详细的使用文档,也有人做了翻译(中文版版本较低),且原理讲解中穿插有相当多的代码实例,有时间的话推荐仔细看下。以下简要介绍几个关键组件及其作用。
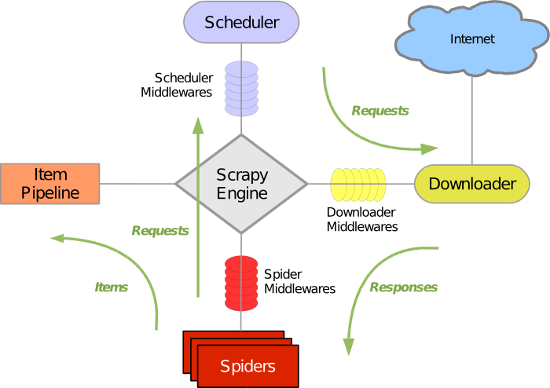
关键组件
Scrapy Engine
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
Scheduler
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
Downloader
下载器的主要职责是抓取网页并将网页内容返还给 Spiders。
Spiders
Spiders是由用户自己定义用来解析网页并抓取制定URL返回内容的类,每个Spider都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
Spider的整个抓取流程是这样的:
(1)首先获取第一个URL的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用start_requests()方法完成的。该方法默认从start_urls中的Url中生成请求,交由回调函数处理。当然也可以自己重写这些函数。
(2)回调函数解析网页响应并返回项目对象item或请求对象request的迭代。即使返回的是request,最终的处理结果也应该是可迭代的item。若是request,这些请求也将包含一个回调,交由下一个回调函数处理。如此循环。这一过程中cookie的传递,item数据的传递,由request中meta的对应参数完成,如
|
(3)在回调函数中,解析网站内容使用的是Xpath选择器,并生成解析的数据项,存储于item中。
(4)最后,由pipelines来处理返回的item,可以直接打印输出,存储到csv,json文件中,或存储到mysql中。
Item Pipeline
项目管道的主要责任是负责处理从网页中抽取的item,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几 个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要 在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
- 清洗HTML数据
- 验证解析到的数据(检查项目是否包含必要的字段)
- 检查是否是重复数据(如果重复就删除)
- 将解析到的数据存储到数据库中
Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式 来拓展Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
Spider middlewares(spider中间件)
spider中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy 的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
网站分析
模拟登陆
为了分析登陆时后台所做的操作,可以先输入错误的登陆信息,观察后台的响应,如果你也用的是chrome,按F12即可调出检测工具。
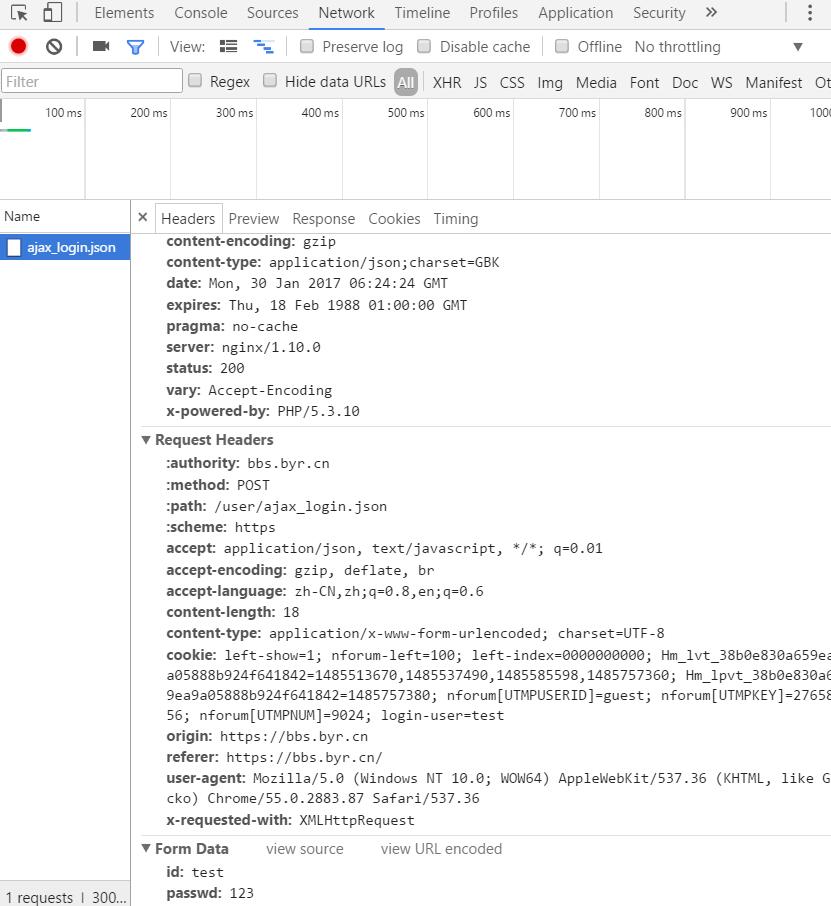
进入Network选项卡,然后输入错误登陆信息,发现有个ajax_login.json文件出现,而Headers中所传入的Form Data的id和passwd就是刚才输入的账号密码。可以确定此文件跟登陆有密切关系。
传递cookie
为了保持登陆,需要传递cookie。与request的值传递类似,cookie的传递也用到了meta,具体见代码。如果想看cookie的传递信息,可在settings中设置COOKIES_DEBIG=True。
板块相关文件与逻辑分析
既然要爬取所有帖子,首先就要有所有的板块链接。论坛的讨论区共有10个一级板块。
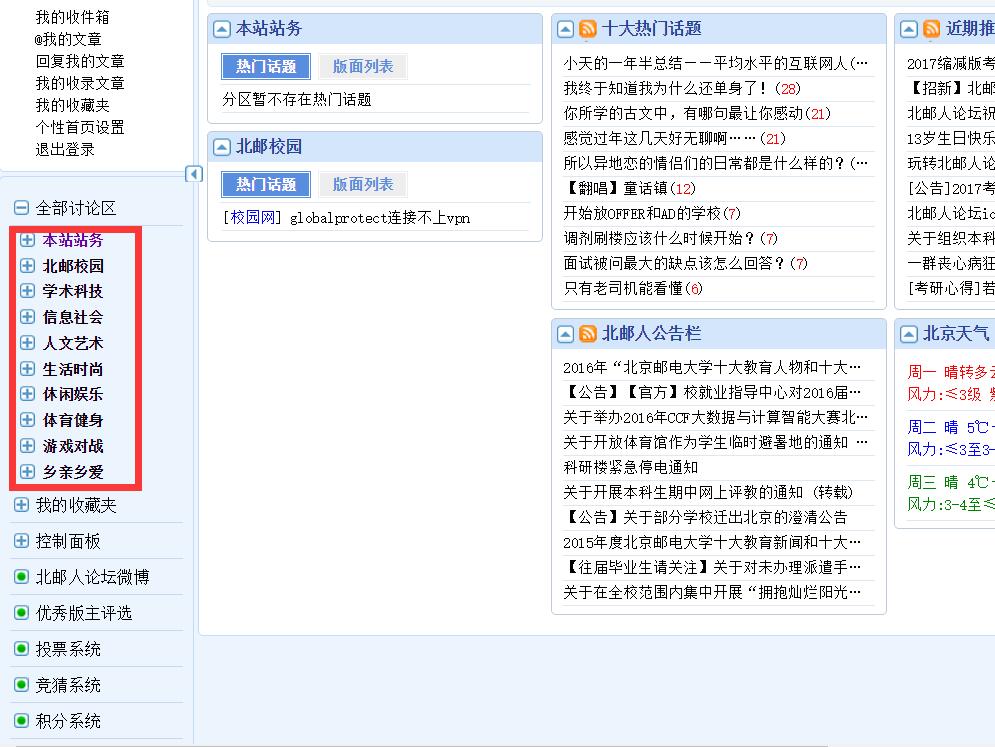
当打开第一个板块的“+”,会生成ajax_list.json?……文件(红框所示),打开第二个板块,对应文件的链接的sec为1
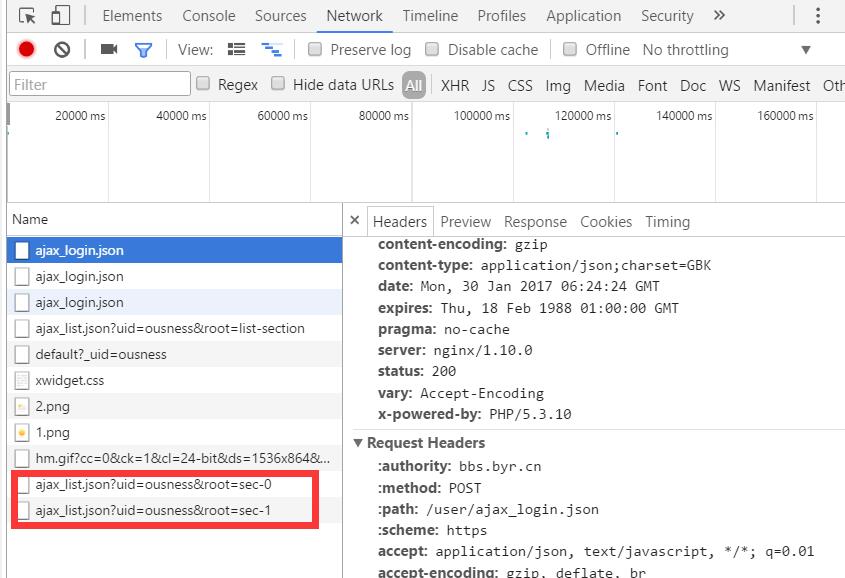
稍微熟悉些http/https的应该能分析出来,打开一级板块的“+”,后台会向ajax_list.json发起post请求,携带的信息(?后面部分)为uid和root,uid为用户名,root的形式为“sec-X”,X取值为0到9,对应第一到第十个一级板块。当然也可以不这么麻烦,直接构造出10个板块的请求链接,即修改sec-后面的数字。
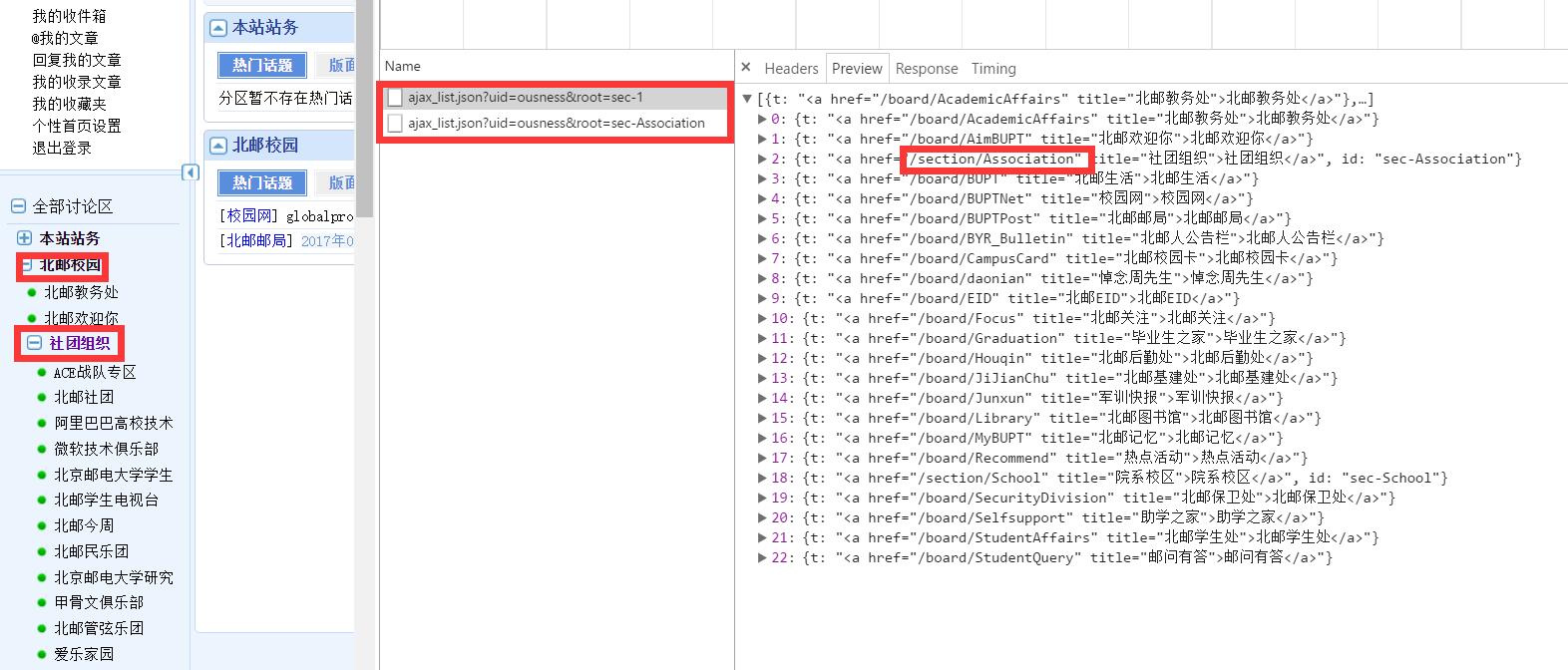
一级板块有10个,每一个板块下可能还有类似的统领型板块(由几个小版块组成),如[北邮校园]下,[北邮教务处]之下就是具体帖子了,但[社团组织]下还能细分出很多板块。可以理解成我们想看一台电脑上10个文件夹下的所有文件内容,但这些文件下有的打开后就能看到文件,有的则是文件夹嵌套,需要打开很多次才能看到文件。至于判断一个板块否是统领型板块,这个可以通过ajax_list.json中的板块链接进行区分。
正式开始
新建项目与数据库
使用scrapy shell创建项目及其他常用命令
|
爬虫写好后,用crawl命令运行,如果你像我一样使用pycharm写的爬虫,不想要再开个shell窗口运行crawl,可以把这条命令写到一个.py文件中:
|
创建数据库表格
|
代码分析
文件目录结构
|
- 详细源码: byrbbs
关键点分析
模拟登陆与cookie传递
|
在scrapy文档中也写有这种方式登陆,将登陆数据,headers等信息传给FormRequest。后续cookie的传递与logged_in函数中的方法一致,通过meta中的cookiejar,而值传递通过其中的item。
文章的处理
|
MySQLdb的使用
|
使用装饰器,为不同的item指定pipeline
spider爬取完数据并生成了item,就会传出给pipeline。当有多个爬虫时,就会有多个item,多个pipeline,而所有的item都会按照settings.py文件中设定的顺序依次经过每个pipeline处理。如果你不想让item经过所有的pipeline处理,就需要为item进行指定pipeline操作。这种类似于权限检查的功能可以用装饰器轻松完成。由于我的一个爬虫只对应一类item,所以我的标记是存在了spider上,当然也可以存在item上。
(1) settings.py中启用pipeline
|
(2) spider中指定此爬虫后续想要使用的pipeline,进行标记。
|
(3) 装饰器,通过spider上的标记完成检测
|
LOG的设置
可以在运行shell指令时添加附加设置,但我更习惯在settings.py中写清楚:
|
|
在代码中添加日志消息:
|
在spider中添加日志消息:
|
执行结果
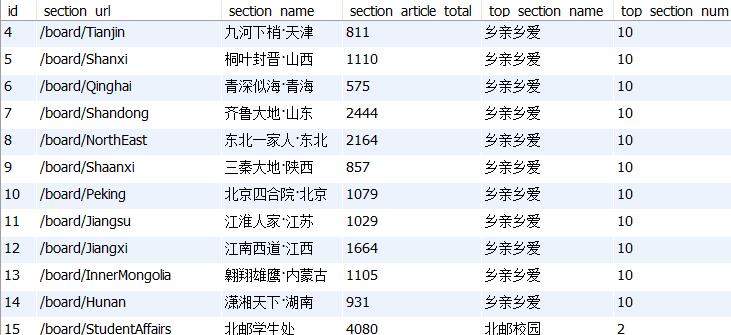
section table
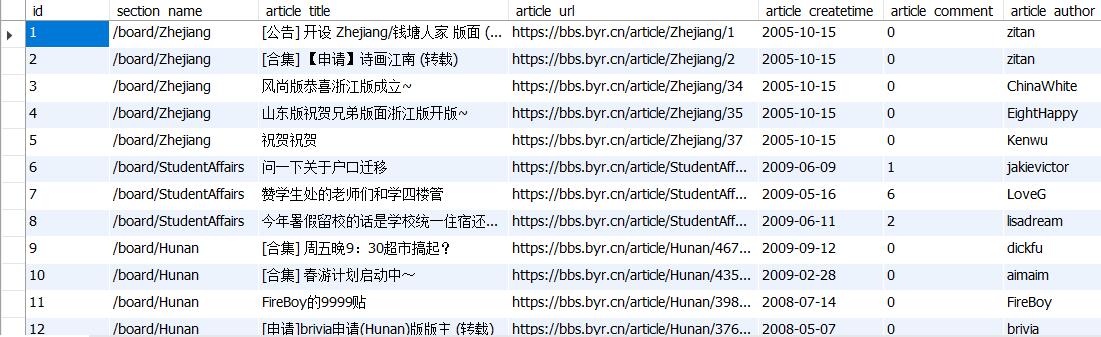
articleinfo table
articlebody table


